
�S�����Z��ģ�͵ďV�����ã�����ڵͳɱ�Ӳ���ό��F�����ܡ��߲��l�ı��ػ�����ɞ��P�I����vLLM��һ���_Դ�Ĵ��Z��ģ������죬���܉��@���������Z��ģ���������ٶȺ�Ч�ʣ��_�l�߿��Ը���Ч�ز�����\�д��Z��ģ�ͣ����䌦�ڶ�GPU��LLM�ă������Fͻ������Linux����ϵ�y��Intel��vLLM���ṩ�����Ĵ�����E���R���������Ñ��M�б��ز����ģ�ͣ�֧�ֶ��Ñ��ಢ�l�����܃�����
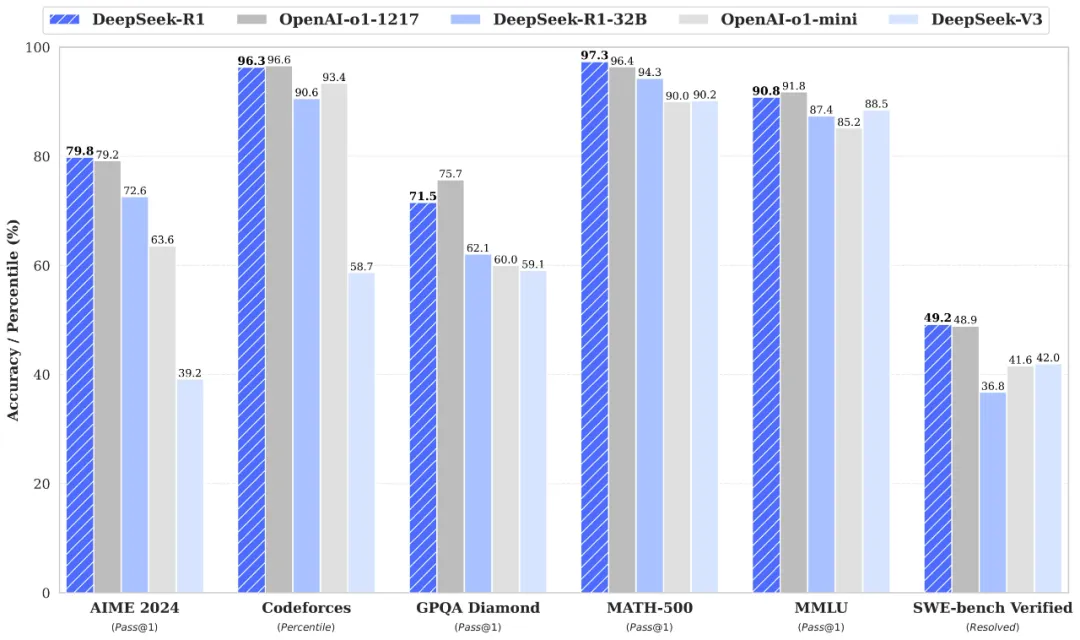
�ڱ����ģ���DeepSeek-R1-32B�ڔ��W���������a�����c߉�����Ȉ������F�Ȟ�ͻ�������y���ܽӽ� 70B ���eģ�ͣ��ɞ�ĿǰDeepSeek���sģ���е����냞�x��
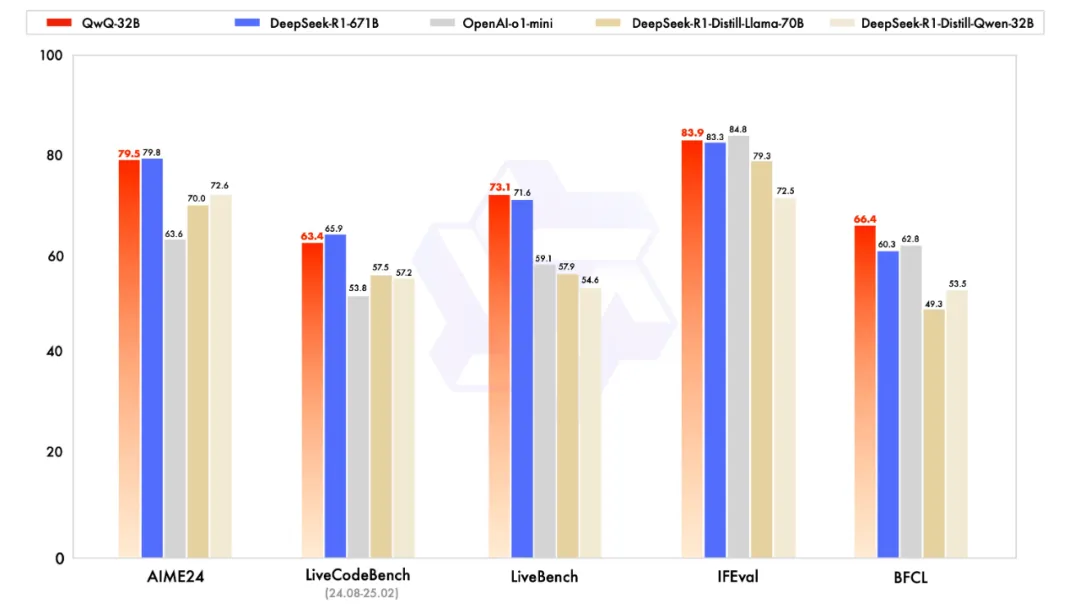
������Qwen�F꠰l����QwQ-32B���Z��ģ�ͣ�һ���Ƴ���V���Pע���ڜyԇ���W������AIME24�u�y���ϣ��Լ��u�����a������LiveCodeBench�У�QwQ-32B���F�cDeepSeek-R1�ஔ���h����o1-mini����ͬ�ߴ��R1���sģ�͡������f��QwQ-32Bģ����Ŀǰ�I����F����ͻ�������V���\�õď����x������������Ԕ����B���ͨ�^Intel��vLLM���ṩ����������������R�ز���DeepSeek 32B��QWQ 32Bģ�͡����ز���32Bģ��ǰ�����ȴ_�J���C�߂�����20G�@���Դ_����ְl�]���ܣ��˴���ʾʹ�õ����Þ飺

���������C���óɱ��H�s11720Ԫ�𣬾߂�������ԃr�ȃ��ݣ�
���ز���DeepSeek 32Bģ�;��w���E��
1���_�JOS�汾����Ubuntu 22.04 + Intel Out-of-Tree GPU drivers.
2����BIOS�O���У��ҵ�“PCI Express Configuration”���Ҵ��_“PCIE Resizable BAR Support”
3���M��UBUNTU���b��
1�����bUbuntu22.04.1+Kernel 6.5.0-35-generic
—���dhttps://old-releases.ubuntu.com/releases/22.04.1/ubuntu-22.04.1 desktop-amd64.iso
—ʹ�ß�䛹��� (����rufus) �턓��U-Disk
—���bUbuntu
—�_���W�j��������ʹ��
2�����b Intel Out-of-Tree GPU driver
· # Install the Intel graphics GPG public key
· wget -q0 - https://repositories.intel.com/gpu/intel-graphics.key |
· sudo gpg --yes --dearmor --output /usr/share/keyrings/intel-graphics.gpg
· # Configure the repositories.intel.com package repository
· echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy unified" |
· sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
· # Update the package repository metadata
· sudo apt update
· sudo apt install -y intel-i915-dkms intel-fw-gpu
3��Configuring Render Group Membership
· sudo gpasswd -a ${USER} render
· sudo reboot
4����CIntel® Arc™ A770 PCIe Configuration Space
· #List the VGA device PCIe bus address to confirm 2x A770s are detected
· sudo lspci | grep -i vga
o 03:00.0 VGA compatible controller: Intel Corporation Device 56a0 (rev 08)
o 04:00.0 VGA compatible controller: Intel Corporation Device 56a0 (rev 08)
· sudo lspci -s 03:00.0 -vvv
· #You should see an output as following:
o Capabilities: [420 v1] Physical Resizable BAR
· BAR 2: current size: 16GB, supported: 256MB 512MB 1GB 2GB 4GB 8GB 16GB
5��Install Docker – ��https://docs.docker.com/engine/install/ubuntu/
· # Add Docker's official GPG key:
· sudo apt-get update
· sudo apt-get install ca-certificates curl
· sudo install -m 0755 -d /etc/apt/keyrings
· sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
· sudo chmod a+r /etc/apt/keyrings/docker.asc
· # Add the repository to Apt sources:
· echo
· "deb [arch=$(dpkg --print-architecture) signed- by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu
· $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" |
· sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
· sudo apt-get update
· sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx plugin docker-compose-plugin
4��Huggingface ���d 32B-AWQ ģ��
1���L��
https://huggingface.co/Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ
2�����dģ�͵��ļ�Ŀ�/model������]��ԓĿ䛣�Ո��rootģʽ����/model��
3�������R����_�����ѽ�����ς����ٶȾW�P��ͨ�^�W�P�������ļ���model.zip 朽�: https://pan.baidu.com/s/1a019IPXap5OmnPM9WICwBg?pwd=mp8w ��ȡ�a: mp8w
5���d���R��
1���d��Intel�ṩ��LLM����R��
—��ipex-llm-serving.tar.gz ��ؐ�����C
—���ddocker�R��sudo docker load -i ipex-llm-serving.tar.gz
2���d��Intel�ṩ��ǰ���R��
—��openwebui.tar.gz ��ؐ�����C
—���ddocker�R��sudo docker load -i openwebui.tar.gz
3���_�J�R����d�ɹ������d�ɹ���sudo docker images ��ԓ���F���´�ӡ��

6����������Pod
1�����Ӻ��������
—��create-llm.sh ��ؐ�����C
—�����_����sudo bash create-llm.sh
—�����һ�΄�������ô�����д�ӡ���@�������F��Error response from daemon: No such container: llm-backend
—�_�Jpod�ѽ����ӣ�

2������ǰ��������
—��create-ui.sh ��ؐ�����C
—�����_����sudo bash create-ui.sh
—�����һ�΄�������ô�����д�ӡ���@�������F��Error response from daemon: No such container: llm-frontend
—�_�Jpod�ѽ����ӣ�

7�����ӑ���
1�����Ӻ�ˑ��ã�
—�½�shell���ڣ���������docker exec -it llm-backend bash /model/ds.sh
—�����_ʼ��ȴ��s����犣����F���´�ӡ���������ӣ�
2������ǰ�ˑ��ã�
—ǰ�ˑ��Þ������Ԇ��ӣ���������docker logs llm-frontend�����F�D�Ĵ�ӡ���ѽ����ӣ�
3���چ�����ǰ��˺���Ҫ�ք��O���@���l�ʺ�CPU�l�ʣ�
— �O��CPU�l�ʣ���Ultra 7 265K����
cpupower frequency-set -d 3.9GHz
—�O���@���l��
xpu-smi config -d 0 -t 0 --frequencyrange 2400,2400
xpu-smi config -d 1 -t 0 --frequencyrange 2400,2400
10������
1���D�ν�����_firefox�g�[����ݔ���ַ127.0.0.1:8080�����D����ǰ����棺
Email�admin@intel.com, Password�admin��ɵ�䛣����������ע�Խ��棬�t���Ղ���ƫ����ɹ���Tע�Լ��ɡ�
2�������˷����������ڵ�ꑺ�������Ͻ������ˆ�������ӵ�ģ�ͣ��c��ģ�����Q����ԓģ�ͣ�
������ϲ������Ì���ģ�ͣ�ݔ��Prompt�����M������������ݔ����
�����Ҫ�M��QwQ-32B-AWQģ�͵ı��ز�����ֻ��Ҫ�������ϲ��E�Ļ��A���M��3��������
1�����dQwQ-32B-AWQģ��
https://huggingface.co/Qwen/QwQ-32B-AWQ�����d��ɺ�ģ�ͷ���/model��
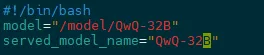
2����ds.sh
3�����Ӻ�ˣ��x��ģ�����Q����ԓģ��
����MS-iCraft Z890 Pacific���d�pIntel Arc A770�@���\��DeepSeek-R1-Distill-Qwen-32B��QwQ-32B-AWQ�Č��C�؈D�����yݔ��Token����27.2/S����֝M���ճ���������
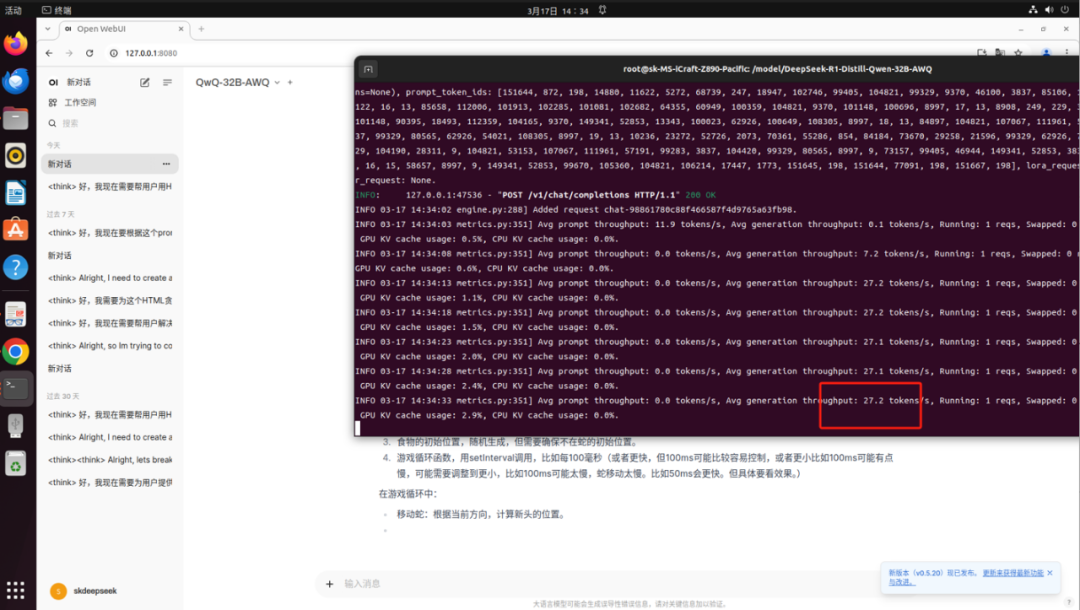
��QwQ-32B-AWQ�\���ٶȌ��C�؈D��
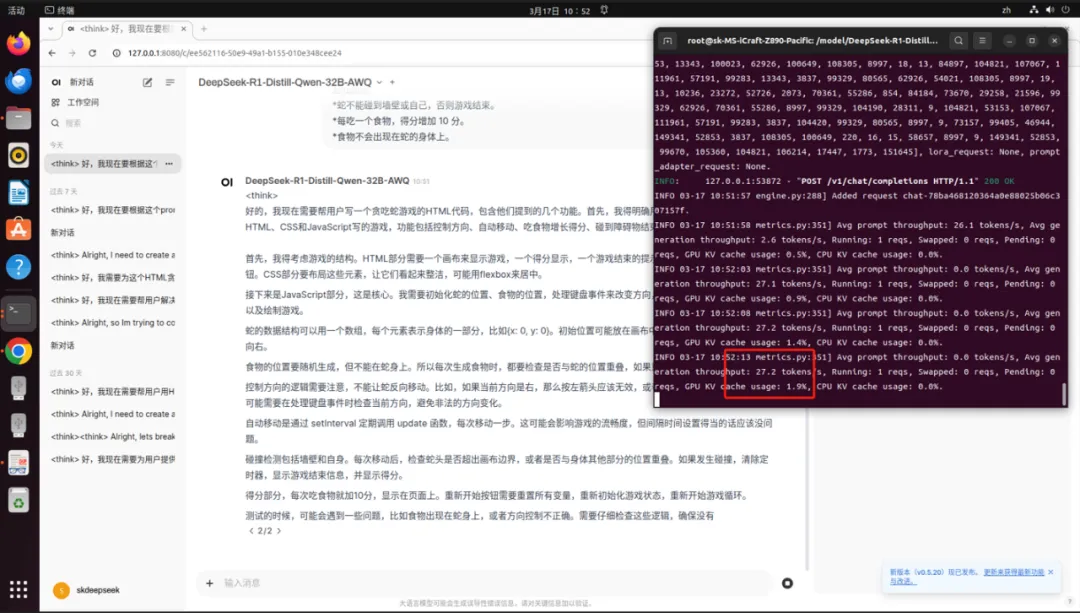
��DeepSeek-R1-Distill-Qwen-32B�\���ٶȌ��C�؈D��
���^��Windows�汾��ͨ�^Linux vLLM�����M�д�ģ�͵ı��ز����ڶಢ�l�����Ͷ���������������@���ݡ�����vLLM�ĺ�˷��տ�ܣ��ܴ���һ��֧��20·���lՈ��·�����ٶ��_10+tokens/s����IAI˽���ƣ�֧�־���W�ȵ������Ñ�ͬ�r�L�������]㑬uZ890��������pIntel Arc A770�@���������fԪ�������ԃr�����C���������FAI����������ݔ����Ч������
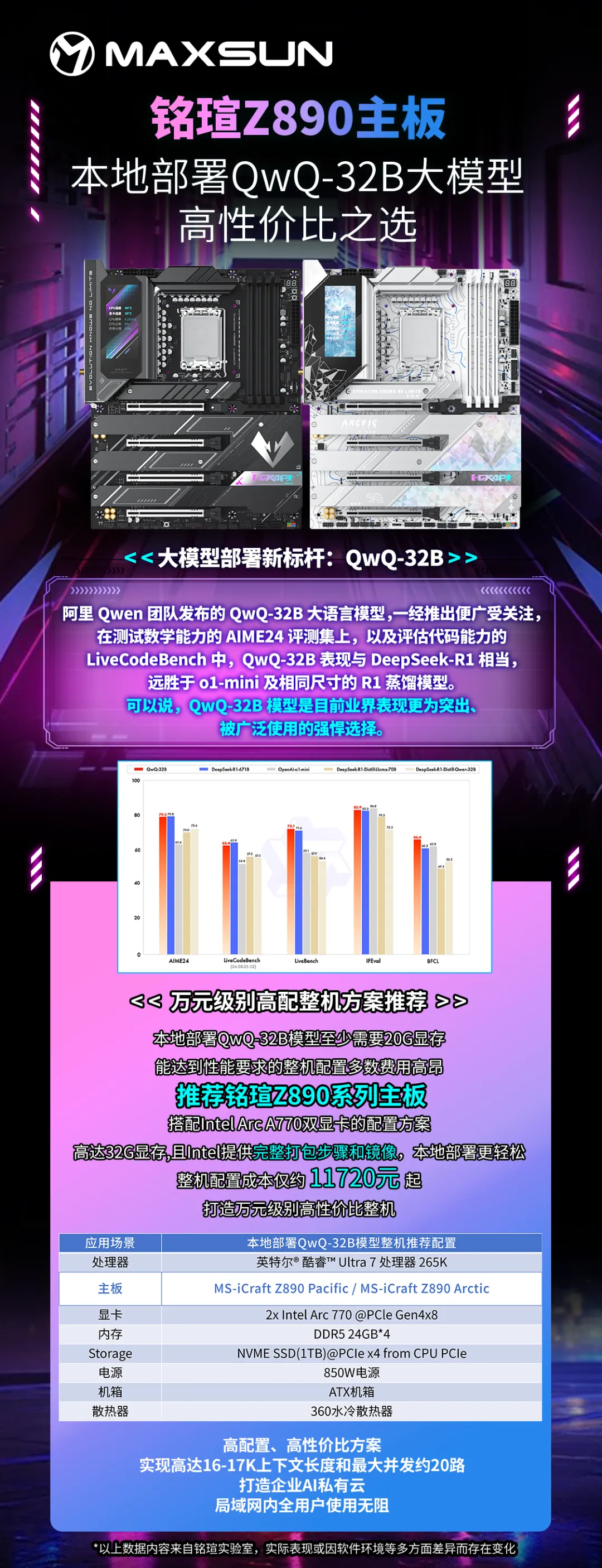
����iCraftϵ���µ����ǮaƷ��MS-iCraft Z890 Pacific��MS-iCraft Z890 Arctic�������һ�K3.4Ӣ���JӰLED�@ʾ����֧�ֶ�Nģʽ�O�ã����˿Ɍ��r�@ʾϵ�y��Ϣ�����Ի��_�P�C�����⣬߀���_������ӳ�䣬ͬ���@ʾ���ٮ����Ӱ��늷��棬����16+1+1��Dr.MOSֱ����늣���ְl�]CPU���ܡ��ȴ淽�棬���4*����DDR5�ȴ��ۣ����l�_��8800MHz��ͬ�r8�ӷ��������͓p��PCB�ͱ��@��ˇ����Ч������̖�p�ġ�������̖�����ԡ�����DDR5���ق�ݔ��

����x��һ��㑬uZ890���壬��ְl�]���ܝ����� 32B ��ģ�͵�����Ч���c���l����ͻ�ƘO�ްɣ�
